Where I clarify my own thinking about GPT-3 outputs and why I think it’s revolutionary.

What is GPT-3?
GPT-3 is a very large parameter (VLP) autoregressive language model trained on 45 terabytes of text, compressed into 175 billion parameters. It cost an estimated $12 million to train (Wiggers, 2020).
What was it trained on?
Mostly English, below are the top 10 out of 119 languages listed in the statistics:
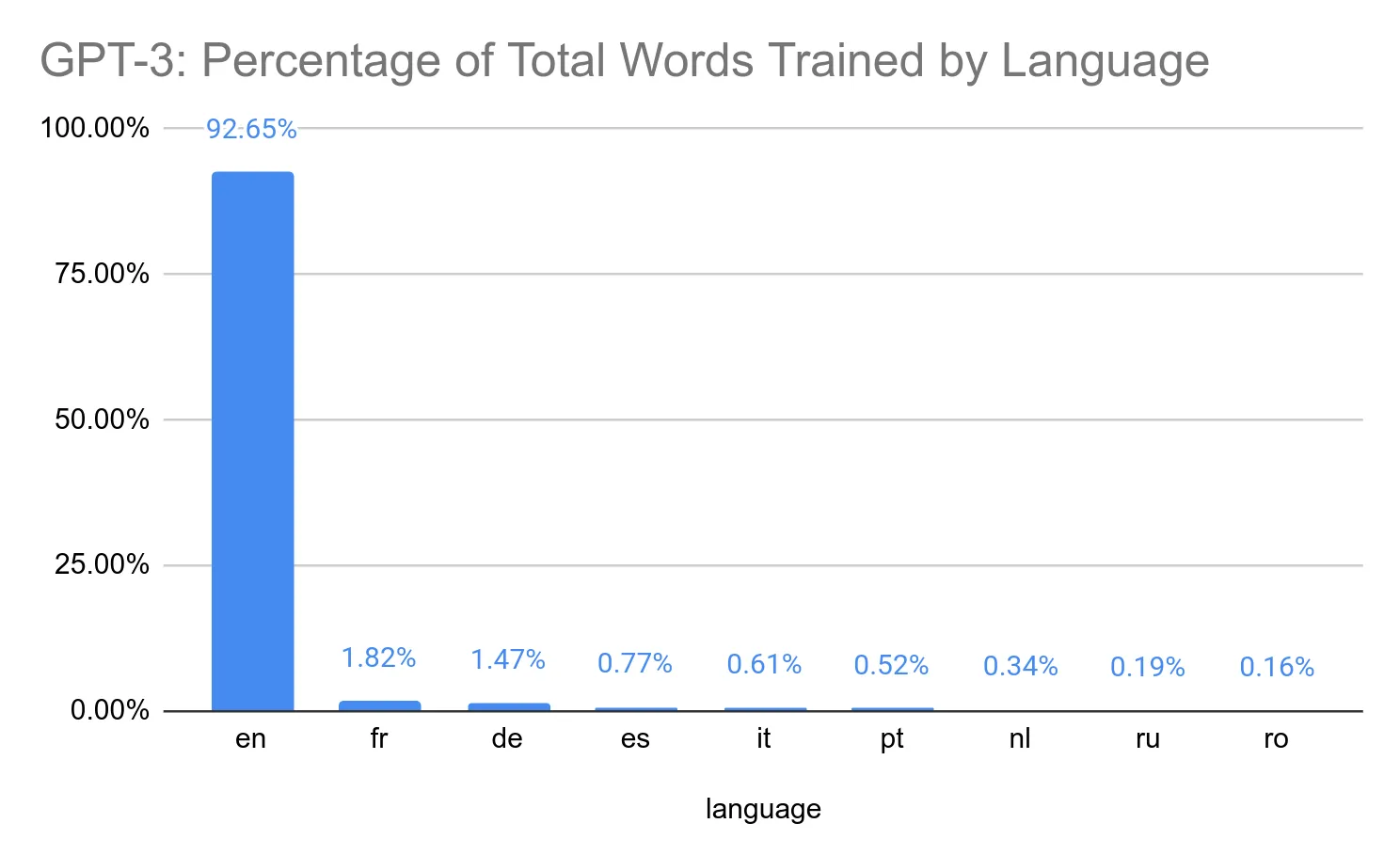
How does it work?
You enter a text prompt and it returns a text sequence. The maximum input and output text is 2048 tokens or about 500-1000 words.
A token is a way of dealing with rare words by breaking a word up into 50k unique subword units using byte pair encoding (BPE) Neural Machine Translation of Rare Words with Subword Units (Sennrich et al, 2015). This is particularly helpful with agglutinative or polysynthetic words where an infinite number of words can be created by combining morphemes. For example, the Yup’ik word tuntussuqatarniksaitengqiggtuq is composed of many morphemes that translate to “He had not yet said again that he was going to hunt reindeer” Describing Morphosyntax: A Guide for Field Linguists (Payne, 1997). Rather than training GPT-3 on tuntussuqatarniksaitengqiggtuq, it is more efficient to train on the BPEs: “t”, “unt”, “uss”, “u”, “q”, “at”, “arn”, “i”, “ks”, “ait”, “eng”, “q”, “igg”, “tu”, “q”. Breaking up words like this has some strange side effects. For instance, GPT-3 performs better at addition when you use a comma as a separator GPT-3 Prompts: Math (Brockman, 2020). BPE encoding may also confuse GPT-3, by obscuring what it needs to understand in the text. For instance, rhyming with GPT-3 continues to be difficult, because phonetics of words are lost in the BPE encoding GPT-3 Creative Fiction (Branwen, 2020).
 by funnyai
by funnyai
Can GPT-3 understand complex subjects?
K Allado McDowell used our GPT-3 toolchain to write Pharmako-AI, the first book to be co-written with GPT-3. It touches on advanced concepts of biosemiotics, hyperspace, and the nature of language. Here is an excerpt of text generated by GPT-3:
The more we can explore our internal experiences of semiosis in relation to life, to machines, and to one another, the more we will be able to make of ourselves, the more we will be able to make of machines, and the more we will be able to make of ourselves in relation to machines. It is not a question of us or machines. It is a question of us with machines. The more we become aware of the true nature of our being, the more we will be able to explore the true nature of our interactions with the universe. We can either choose to be part of the process or to be outside of the process. The process is the true nature of reality. We are already part of the process, and we always have been. It is not our decision to make. We are already here. It is a question of our wisdom in the ways in which we live in this universe. We are only beginning to explore what this may be, and what it may be like.
This sounds like GPT-3 is a believer in CosmoTechnics defined as “the unification of the cosmos and the moral through technical activities, whether craft-making or art-making” from Yuk Hui’s Cosmotechnics as Cosmopolitics essay (2017).

In early October, I worked with 18 artists on the Aikphrasis project. I acted as a co-curator working with GPT-3 to tailor ekphrastic phrases specific to an artist’s practice. One person couldn’t believe their phrase was computer generated, another thought that GPT-3 had definitely trained on his blog as the phrase was exactly what he aspires to do. Another artist was brought to tears by the words generated. Many of the artists were “absolutely inspired” by the text and you can see their amazing creations in painting, poetry, sculpture, video, and theatre.
 by
by It’s composed of weights (numbers).
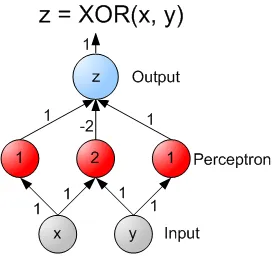
How can this language model understand anything if it is just numbers?
When you first learn about neural networks, you find that you can only approximate linear functions with a single layer neural network. When you move to a two-layer neural network, it can express non-linear concepts like exclusive or (XOR) The “hello world” of neural networks (Hollemans, 2016).
The XOR is a simple two-layer illustration of the Universal approximation theorem that states that any mathematical function can be replicated by a neural network with enough appropriate weights.
The notion that everything in the universe can be reduced to probabilities was explored in the introduction of 30 Years after Les Immatériaux: Art, Science, and Theory (Hui and Broeckmann, 2015):
In quantum mechanics, Heisenberg’s uncertainty principle claims that we cannot know the location and speed of a particle simultaneously. Speed and location are two important concepts in classical mechanics, since it is the displacement of location and duration that gives us velocity and acceleration.The presence of particles can now only be imagined in terms of probabilities. This involves both a mathematical reduction as well as a dematerialisation of objects in our universe, including stars, galaxies, bodies and mind. For example, the first seconds of the birth of the universe are represented by means of a quantifiable model with which we can explain the genesis of the cosmos, as if there were human subjects who witnessed the process.
The Bayesian brain hypothesis posits that the human brain processes sensory input and updates its internal model of the world using probability theory The Brain as a Statistical Inference Engine—and You Can Too (Charniak, 2011).
Was this written with GPT-3?
No, but yes. My mind has been altered by GPT-3 outputs.