GeoMorphs

GeoMorphs is a generative art project built during a 2021 Artist in Residence at Planet [medium.com]. It’s a generative adversarial network (GAN) trained on Planet [planet.com] satellite images.
My residency started with some amazing virtual interactions with the scientists and technologists at Planet. Dr. Tanya Harrison and I talked about possible art projects and her work with Mars missions. I chatted with Rob Simmon on how to take data that is difficult to understand and present it in a form that an audience can appreciate. Andrew Zolli and I discussed deforestation, planetary ethics, land stewardship, and indigenous guardianship. Ash Hoover showed me how to use machine learning to analyze floods, deforestation, wildfires, methane, ships, and building construction. Işıl Demir talked about mission control, smart automation, and ground stations. Sara Safavi showed me how to search and access Planet imagery. Orestis Herodotou talked about machine learning and art, including a work he showed at Gray Area. Dr. Ariel Zajdband showed me how to calculate different vegetation indices for determining crop health, estimating production, and precision agriculture in tropical areas. I appreciate that so many Planeteers were able to take time out of their busy schedule to meet with me.
If you are interested, I would highly recommend applying to their Artist in Residence Program [planet.com].
Dataset
After I trained an initial model with a few thousand satellite images, I showed the Planeteers my results. Dr. Joe Kington then provided me with 190,000 Planet satellite images that were 1024x1024 in size. Planet runs a classifier originally written by Kat Scott [twitter.com] on every scene they ingest. Categories are then applied to each scene based on histogram and color derived features. He selected scenes with the “interesting” class defined by scenes that were liked/favorited using Planet’s internal tools. Here are some sample images:
 Sample images from Planet’s 1024x1024 Dataset
Sample images from Planet’s 1024x1024 Dataset
Stylegan2-ada Results
 StyleGAN2-ada Generations
StyleGAN2-ada Generations
The state-of-the-art model for “Training Generative Adversarial Networks with Limited Data [arxiv.org]” is StyleGAN2-ada [github.com] by Tero Karras et al. presented at NeurIPS Conference in 2020. The model trained quickly and captured complex coloration and textures. Unfortunately, it provided very little variation of form. In the image above, you can see there is a consistent diagonal from the upper right to the lower left.
I reviewed the curated example images provided by the developers of the StyleGAN2-ada model. There was only one dataset that was not aligned to facial landmarks, the BreCaHAD model. It also had a limited variation of form where the same diagonal from upper right to lower left appears:
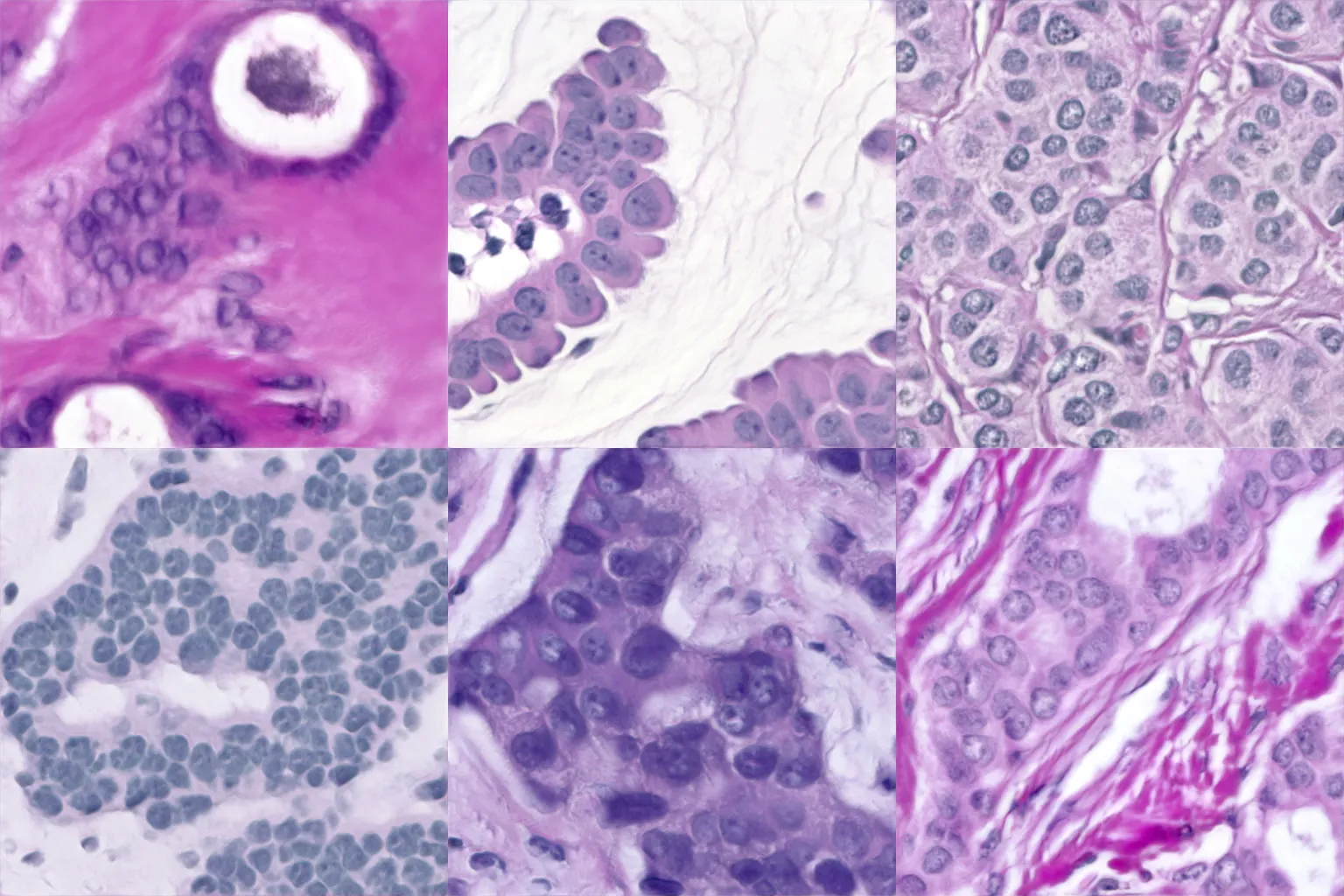 StyleGAN2-ada BreCaHAD Generations
StyleGAN2-ada BreCaHAD Generations
Justin Pinkney had a twitter post discussing this issue on a StyleGAN2 model. He found that the generated flowers for his model all had “two blobs at the top and a smaller one between them”. His solution is to modify the noise tensor [twitter.com] in addition to the z latents.
This definitely helped the form, but I still believed the StyleGAN2-ada model was flawed as non-aligned datasets like horses and cars were not trained or highlighted by StyleGAN2-ada. Instead, I decided to train a StyleGAN2 (non-ada) model from scratch to see if I could get a wider variety of image forms.
Final Model - StyleGAN2
 StyleGAN2 Generations
StyleGAN2 Generations
I was very pleased with the variation of color, texture, and form in the StyleGAN2 [github.com] model by Tero Karras et al. trained from scratch.
Using Principal Component Analysis (PCA), you can begin to explore latent space of a model. I used GANSpace [github.com] built by Erik Härkönen et al. to look at the different components. Here are results of adjusting component #0 for five images:

Here are results of adjusting component #1 for five images:

SampleRNN
I also trained an audio model to generate low bass sounds using a SampleRNN [github.com] model designed by Mehri et al. and built by Unisound. I trained on wind, ocean, and hydrothermal recordings.
Final Works
The final piece will be an audio reactive piece that uses the generated sound to walk through latent space. I’m using code written by Hans Brouwer for his paper Audio-reactive Latent Interpolations with StyleGAN [github.com].
Here are the onsets from the sound I generated:
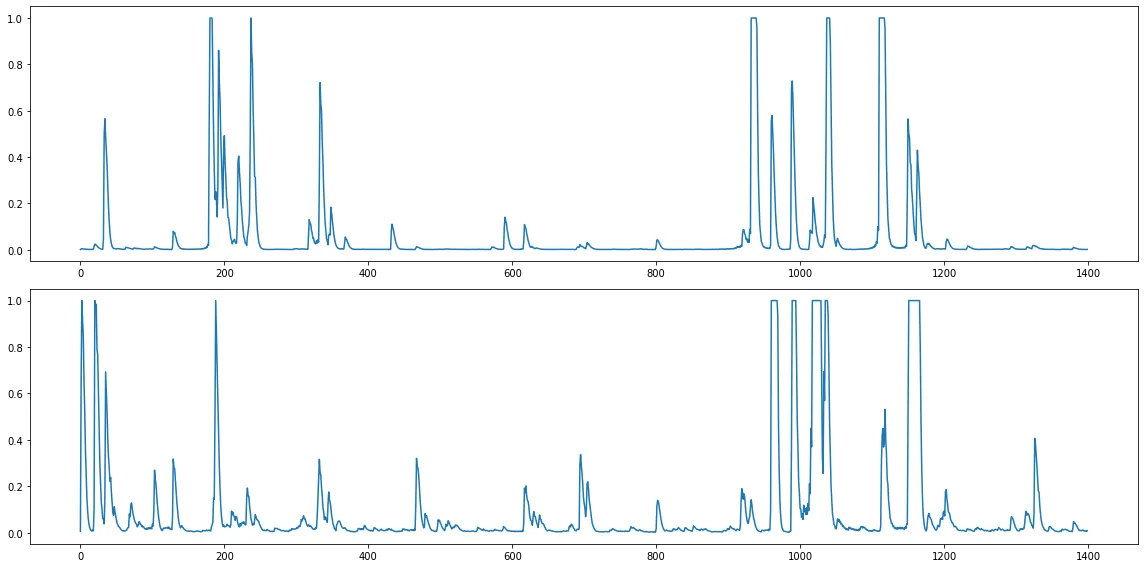
And the chroma:
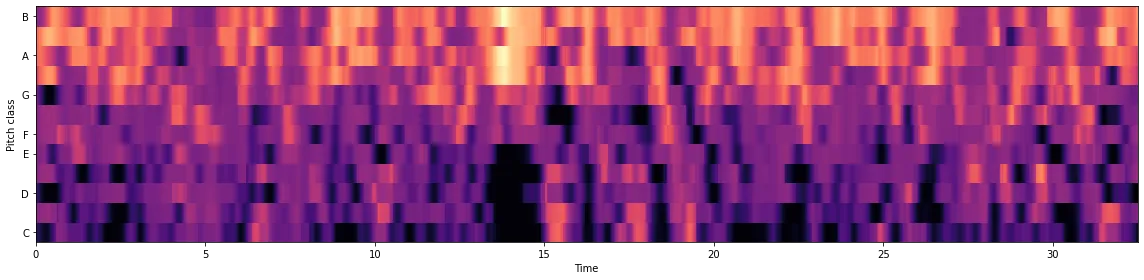
Here is a sample of what was generated:
I’m still working with Planet on how best to show the work in their space. Stay tuned!
Acknowledgements
I would like to thank Orestis Herodotou, Dr. Tanya Harrison, Andrew Zolli, Joe Kington, Rob Simmon, Ash Hoover, Claire Bentley, Julie Kuschke, Sara Safavi, Işıl Demir, and Dr. Ariel Zajdband at Planet for their support on this project.