Using WaveNet, a deep neural network, I was able to synthesize a ten second clip of Sylvia Plath’s voice. WaveNet was trained without text sequences, so the generated speech is gibberish:
Dataset
The network was trained on 1000+ audio clips from 80 minutes of poetry spoken by Sylvia Plath. Here is an example of one of the clips:
To create the clips, I used Audacity to break up the ~30 minute MP3 files into smaller clips using “Sound Finder”:
I then listened to clips below 30k in file size, and deleted any clips that are silent.
Training
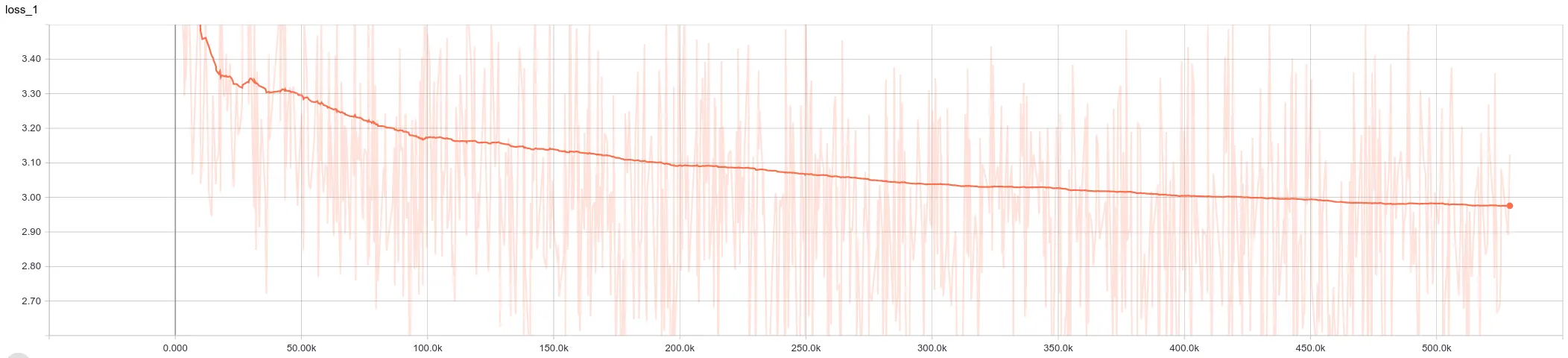
The batch size was set to 2 for a 2GB GPU. There was a lot of jitter, but the loss continued to descend after 500k steps: