Generative Adversarial Imitation Learning (GAIL)
Imitation Learning or learning from expert trajectories can be implemented two different ways:
- Behavioral Cloning
- a supervised learning problem that maps state/action pairs to policy
- requires a large number of expert trajectories
- copies actions exactly, even if they are of no importance to the task
- Inverse RL
- learns the reward function from expert trajectories, then derives the optimal policy
- expensive to run
- indirectly learns optimal policy from the reward function
GAIL
GAIL is not exactly Inverse Reinforcement Learning because it’s learns the policy, not the reward function, directly from the data. Yet, it’s better than Behavioral Cloning and sometimes better than the experts, because it’s doing Reinforcement Learning and it’s not constrained to always be close to the expert.
GAIL, similar to a Generative Adversarial Networks, is composed of two neural networks. The Policy (Generator) network pi-theta is trained using TRPO and the discriminator network D is a supervised learning problem trained with an ADAM gradient step on expert trajectories. Both networks have two hidden layers of 100 units each with a tanh activation.
The goal is to find a policy pi-theta such that the discriminator cannot distinguish between states following the pi-theta as opposed to those from pi-expert.
Steps to train GAIL
- Sample the expert trajectories
- Optimize the Policy pi-theta
- Optimize the Discriminator D
I used OpenAI’s Baseline GAIL code to train on MuJoCo: https://github.com/hollygrimm/gail-mujoco
Results
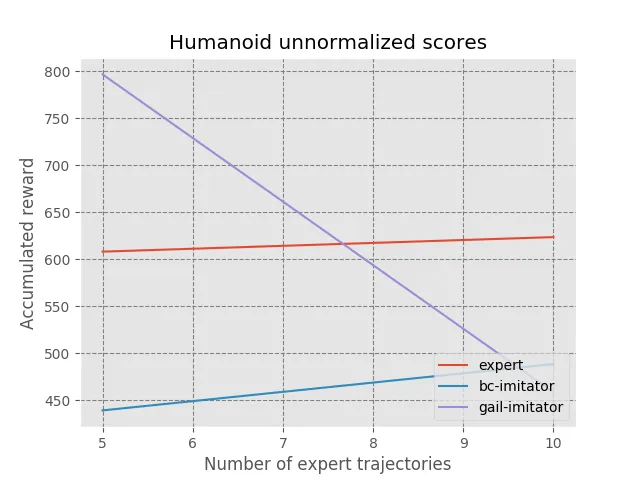
I ran GAIL and Behaviorial Cloning on the following MuJoCo environments: Humanoid, HumanoidStandup, and Hopper. With five expert trajectories on Humanoid, GAIL was able to get better than “expert” results. These tests were run with only one seed, I would need to run many more seeds to make a conclusive statement.
HumanoidStandup Trained on GAIL
References
- Sergey Levine. “CS294 Inverse reinforcement learning”. Video | Slides
- Ng et al. “Algorithms for Inverse Reinforcement Learning”. PDF.
- Fu et al. “Learning Robust Rewards with Adversarial Inverse Reinforcement Learning”. PDF.
- Ziebart et al. “Maximum Entropy Inverse Reinforcement Learning”. PDF.
- Wulfmeier et al. “Maximum Entropy Deep Inverse Reinforcement Learning”. PDF.
- Finn et al. “Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization”. PDF.
- Ho et al. “Generative Adversarial Imitation Learning”. PDF.