
Abstract: I consider how to influence CycleGAN, image-to-image translation, by using additional constraints from a neural network trained on art composition attributes. I show how I trained the the Art Composition Attributes Network (ACAN) by incorporating domain knowledge based on the rules of art evaluation and the results of applying each art composition attribute to apple2orange image translation. Finally, I show how this network may be used to generate art by applying the CycleGAN + ACAN to one of my paintings.
1 Introduction
CycleGAN’s image-to-image translation [1] takes one of set of images and tries to make it look like another set of images. The training data is un-paired, meaning there doesn’t need to be an exact one-to-one match between images in the dataset. This Generative Adversarial Network has been used successfully to make horses look like zebras and apples look like oranges.
For my project, I’m augmenting the standard generator and discriminator losses of the CycleGAN with additional loss terms from a convolutional neural network trained with art composition attributes. During training of the CycleGAN, the user specifies values for each of the art composition attributes. For instance, if a target contrast value of 10 is specified, the generator should output images with more contrast than if the target contrast value is 1.
1.1 Art Composition Attributes
My art teacher, Sherry Rosevear, taught me a comprehensive method of evaluating the composition of artworks. I’ve selected eight art attributes from her technique and labeled 500 images from the WikiArt dataset [2]:
- Variety of Texture (1-10): a value of 1 for paintings with a single texture, 10 for many different textures
- Variety of Shape (1-10): a value of 1 for paintings with only a few shapes, 10 for a variety of different shapes
- Variety of Size (1-10): a value of 1 for paintings that have shapes that are all about the same size, 10 for many different sizes of shapes
- Variety of Color (1-10): a value of 1 for paintings that are monochromatic, 10 for including all the colors in the color wheel
- Contrast (1-10): a value of 1 for low contrast, 10 for high contrast
- Repetition (1-10): a value of 1 for very little repetition of shape and color, 10 for a lot of repetition of shape and color
- Primary Color (black, magenta, red-magenta, red, orange, yellow, yellow-green, green, green-cyan, cyan, blue-cyan, blue, and blue-magenta)
- Color Harmony (monochromatic, analogous, complementary, split complementary, triadic, tetradic)
Here are some examples of low and high values of each attribute in WikiArt dataset:
| Texture:1 | Shape:1 | Size:1 | Color:1 | Contrast:1 | Repetition:1 |
|---|---|---|---|---|---|
 |  |  | 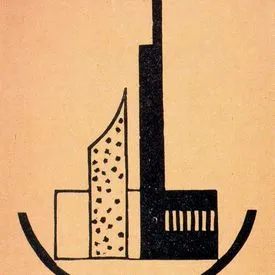 |  |  |
| Texture:10 | Shape:10 | Size:10 | Color:10 | Contrast:10 | Repetition:10 |
|---|---|---|---|---|---|
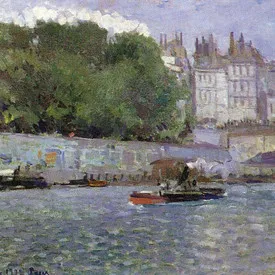 |  |  |  | 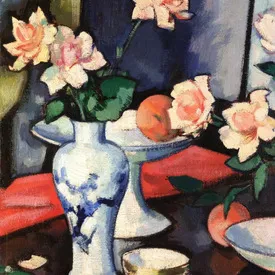 |  |
1.2 Primary Color
When I select colors for my paintings, I prefer to use the cyan, magenta, and yellow (CMY) color wheel instead of the one with red, blue, and yellow primary colors. I like that the CMY color wheel includes more modern colors like magenta and cyan. Also, it aligns better with most printer color models.
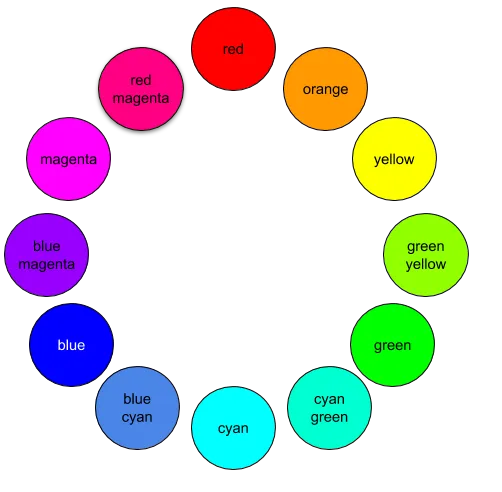
Here are some images from the WikiArt dataset labeled with the primary color in each painting:
| Red | Orange | Yellow | Green-Yellow | Green | Green-Cyan |
|---|---|---|---|---|---|
 |  |  |  |  |  |
| Cyan | Cyan-Blue | Blue | Blue-Magenta | Magenta | Red-Magenta |
|---|---|---|---|---|---|
 |  |  |  |  |  |
1.3 Color Harmony
Here are examples from the WikiArt dataset for each color harmony with orange as the primary color:
| Monochromatic | Analogous | Complementary | Split Comp. | Triadic | Tetradic |
|---|---|---|---|---|---|
 |   |   |   |   |   |
More details about art composition attributes can be found on my Week 9 blog post.
2 Related Work
2.1 Perceptual Loss Functions
Using different loss functions in art generation was done in the paper by Johnson et al, Perceptual Losses for Real-Time Style Transfer and Super-Resolution [4].
In the paper, Johnson et al replaced the standard per-pixel loss function in a style transfer model with perceptual loss functions. These loss functions were based on the high-level image features extracted from pre-trained CNNs. The perceptual information had already been encoded in these networks and they were used to create high-quality images.
2.2 Learning Photography Aesthetics with Deep CNNs
My deep CNN for learning painting composition attributes is based on the paper, Learning Photography Aesthetics with Deep CNNs by Malu et al [5]. For photography, they are training on the aesthetics and attribute database (AADB) which has the following attributes: Balancing Element, Content, Color Harmony, Depth of Field, Light, Object Emphasis, Rule of Thirds, and Vivid Color. The photography principles are quite different from the painting attributes that I’m training on.
3 Method
3.1 Art Composition Attributes Network (ACAN)
Code. I have made my code for this network publicly available here: https://github.com/hollygrimm/art-composition-cnn. Details on how I added multiple outputs to a Keras ResNet50 model can be found in my Week 11 blog post
Inputs. Five hundred WikiArt 256x256x3 pixel images labeled with eight attributes. Six of the attributes, variety of texture, variety of shape, variety of size, variety of color, contrast, and repetition, have numerical values between 1 and 10. The other two attributes are primary color composed of 13 classes and color harmony which has 6 classes.
Model. Fine tuning of a ResNet50 [3] pretrained on the ImageNet dataset. ResNet50 is a fifty-layer deep residual network. There are 16 residual blocks. Each block has three convolution layers, followed by batch normalization, then an activation layer.
Global Average Pooling (GAP) is applied to the ReLU output from each of the sixteen ResNet block activations, called the rectified convolution maps.
The sixteen GAP outputs are concatenated and L2 normalization is applied to create a merge layer. From the merge layer, there are eight outputs, one for each of the attributes.
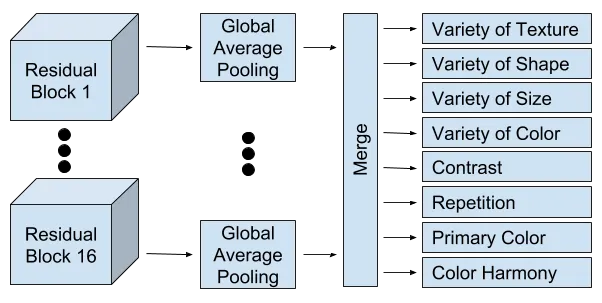
More details about how I added Globabl Average Pooling to ResNet50 can be found on my Week 10 blog post.
Loss Weights. I’m training on a total of eight art attributes. The six numerical values use mean squared error to calculate loss, while the two categorical attributes use categorical cross-entropy.
My first training run found that the model was not learning the repetition value after 200 epochs. It’s validation loss was steadily increasing, although I was able to get some good training results from the other art attributes: variety in size, variety in shape, and variety in texture.
After doing some research, I read that losses from categorical cross-entropy are often higher than those from mean squared error. To remedy this, you can modify the loss weights across the different attribute types and thus help balance contributions of each of the losses.
After my initial training, I found that losses from categorical cross-entropy (color harmony and primary color) were typically seven times higher than those from mean squared error. As a result, I retrained with several categorical attribute loss weights lambda_categorical = [.85, .7, .5, .3] leaving the numerical attribute loss weights the same at 1.0.
By lowering the categorical weights to .7 and training for 1000 epochs, validation losses on the repetition attribute were very good. Primary color losses were better than the .5 loss weights, but not as good as the original 1.0 loss weights.
Training loss charts for repetition and primary color can be found on my Week 12 blog post.
3.2 CycleGAN + ACAN
Code. I have made my code for this network publicly available here: https://github.com/hollygrimm/cyclegan-keras-art-attrs
Inputs. Two sets of images for image-to-image translation, I provide a download script for the standard CycleGAN image sets (apple2orange, summer2winter_yosemite, horse2zebra, monet2photo, etc.)
In addition, target values are selected for each of the art composition attributes.
Discriminator Loss. If the discriminator is passed a fake image, it should output a 0. The discriminator loss is the difference between the output of the discriminator and the actual label of the image. I used a discriminator loss weight of 1.0.

Cycle-Consistency Loss. Cycle-Consistency Loss is the difference between the real apple image and the reconstructed apple image after it’s been transformed by the apple2orange generator, then the orange2apple generator. For this loss, I used a loss weight of 1.0.
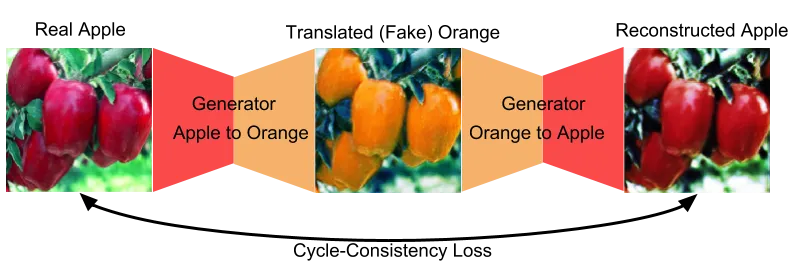
Identity Loss. Identity loss is calculated by running a real orange image through the apple2orange generator and seeing how close the output is to the input. I used a loss weight of .1 for this loss.

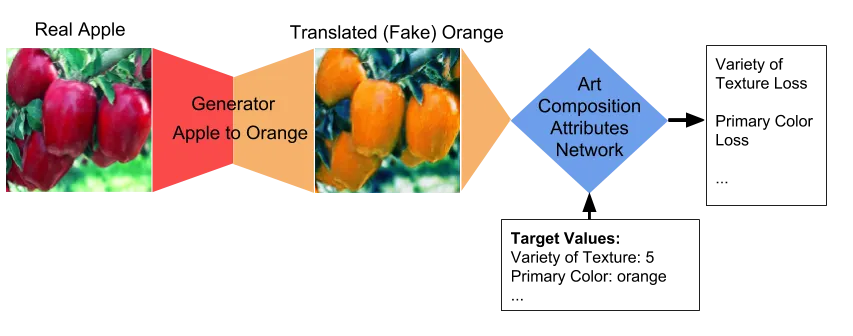
Art Composition Attributes Network (ACAN) Loss. A series of eight losses are generated when the translated image is passed through the ACAN with eight target values. The difference between these target values and the values output by the network are the attribute losses. In the examples below, the loss weight is 10.0.
4 Results
Below are the results of running the CycleGAN training with the ACAN. Each art composition attribute below was run with a loss weight of 10.0, along with a low value of 1 or a high value of 10. The output image is either the translated or reconstructed version from the CycleGAN:

4.1 Variety of Texture
| This pair is an example of setting variety of texture to the lowest value of 1. The texture of the reconstructed version (right) has very soft texture, like an oil painting. |  | |
|---|
| The reconstructed image here was generated with a value 10 for a high variety of texture. As a result, the texture of the apple skin has been enhanced. | |  |
|---|
4.2 Variety of Shape
| By setting the variety of shape to the lowest value of 1, the network has abstracted the reconstructed version (right) into some flat orange shapes. |  |  |
|---|
| Setting the value of variety of shape to a high value of 10, the reconstructed version has highlighted many distinct shapes within the image. | |  |
|---|
4.3 Variety of Size
| With a low value for variety of size, the reconstructed version has limited the size of shapes to only a few. |  |  |
|---|
| The translated version, set to a high variety of size, has found some smaller details to highlight, in addition to the larger shapes. | |  |
|---|
4.4 Variety of Color
| When setting variety of color to a low value, the reconstructed version has been transformed into a monochromatic image with all reds. | |  |
|---|
| The translated image, with a setting for a high variety of color, has included bright blues, reds and yellow-greens. | |  |
|---|
4.5 Contrast
| Training on low contrast, the reconstructed version has flattened the background and lightened the entire apple. | |  |
|---|
| Training on high contrast, the reconstructed version has darkened the shadows and highlighted parts of the apple and background. | |  |
|---|
4.6 Repetition
| The reconstructed image on the right is an example of training with low repetition of form, color, and texture where these attributes have been abstracted. | |  |
|---|
| The reconstructed image here was trained with a high value for repetition of form, color, and texture. The same textures, colors, and forms have been repeated throughout the whole image. | |  |
|---|
4.7 Primary Color
| The reconstructed image has added some areas of the target color, blue cyan. | |  |
|---|---|---|
| Here, the reconstructed image was changed to the target color of yellow. | |  |
4.8 Color Harmony
| The translated image, with a primary color of orange, has included the analogous colors of yellow, red, and green-yellow. | |  |
|---|---|---|
| The translated image, also with a primary color of orange, has a patch of the complementary color of blue-cyan. | |  |
| The translated image is now almost all one color, red. | |  |
4.9 Art Generation
Below is the result of using the CycleGAN + ACAN. I input CelebA [6] images for one dataset, and my paintings for the second dataset. All the art composition attributes were set to value 5, primary color to orange, and color harmony to analogous:

5 Conclusion
Even with a small sample size of 500 images, the CycleGAN with help from the ACAN appears to have been able to distinguish between eight art compositional attributes.
6 Next Steps
I will run some additional experiments by transforming my paintings though CycleGAN + ACAN with different settings.
6.1 Attribute Activation Mapping
Malu et al’s paper [5] outlines how to perform attribute activation mapping by using the rectified convolution maps to apply a heat map which highlights elements that were activated by each attribute. It will be extremely useful to see what the network “sees” for these attributes.
6.2 Color and Color Harmony Embeddings
Primary color and color harmony have associations between their classes. If the model chooses red for a primary color, and the actual label is red-magenta, then the model is closer than if it chose green. I’d like to represent each color and color harmony as a 10-dimensional embedding vector. This should allow the CNN to learn associations between colors on the color wheel.
Thank you!
Thank you to OpenAI for allowing me to jump-start my career in Machine Learning with the OpenAI Scholars program. I was very appreciative of the weekly support I received from my mentor, Christy Dennison from OpenAI. Larissa Schiavo, the program manager at OpenAI, was great in providing us the tools needed to be successful during the program.
I’d also like to thank my fellow Scholars, Christine Payne, Dolapo Martins, Hannah Davis, Ifu Aniemeka, Munashe Shumba, Nadja Rhodes, and Sophia Arakelyan for their inspiring projects and helpful suggestions.
Thank you to Josh Achiam, OpenAI, for reviewing my final project and providing suggestions and Jack Clark, OpenAI, for help on writing tools.
References
- Zhu et al, Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks https://arxiv.org/pdf/1703.10593.pdf
- Kaggle’s WikiArt “Painter by Numbers” dataset https://www.kaggle.com/c/painter-by-numbers/data
- He et al, Deep Residual Learning for Image Recognition https://arxiv.org/pdf/1512.03385.pdf
- Johnson et al, Perceptual Losses for Real-Time Style Transfer and Super-Resolution https://arxiv.org/pdf/1603.08155.pdf
- Malu et al, Learning Photography Aesthetics with Deep CNNs https://arxiv.org/pdf/1707.03981.pdf
- CelebA Dataset http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html